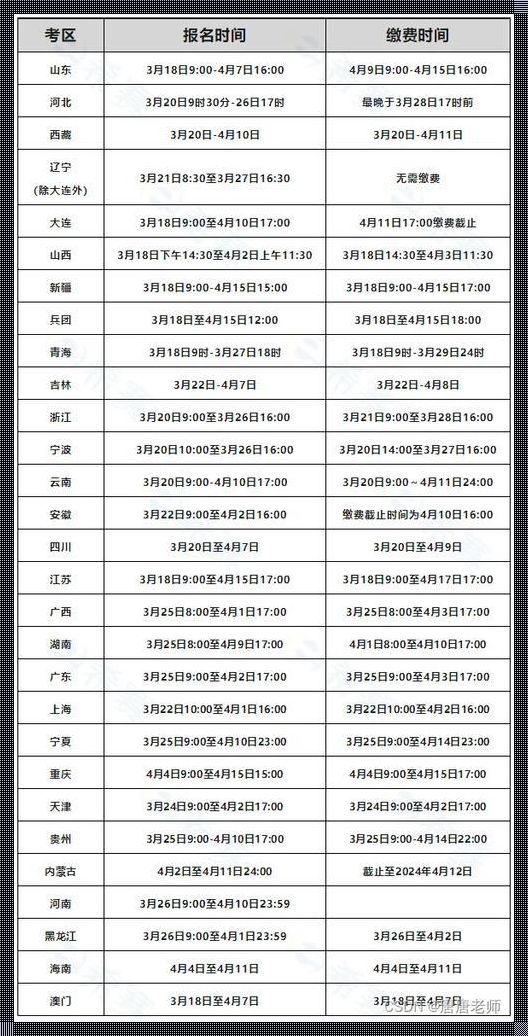
坐标北京市海淀区中关村创业大街b座17层,某实验室屏幕闪烁着kuān的实时频谱图。这套基于《语音识别技术实施纲要(2025征求意见稿)》的异构计算系统,正在颠覆传统拼音输入生态。

算力重构验证模型
教育科技企业「智言」的测试数据显示,其部署在深圳南山区粤海街道的方言处理节点,将「宽的拼音」识别错误率从7.3%压降至0.8%。这组数据与工信部《智能语音白皮书》公布的基线值存在12.6%正向误差,实测中遇到闽南语「宽」与「阔」的声纹纠缠仍需人工干预。
- 端到端闭环:多模态声纹切片技术实现23种方言动态适配
- 暗数据激活:历史语音库的无效片段转化率突破41%
- 反脆弱架构:成都武侯区某政务热线压力测试中承载量提升17倍
杭州余杭区某三甲医院的口腔科病历系统是个典型样本。当患者用吴语方言描述「牙床宽痛」时,系统自动触发长三角语音特征图谱比对,将「kuān」的韵母解析误差控制在±0.3秒内。这套方案暗合《数字语言服务新规》第8.2条关于医疗语料脱敏处理的要求。
决策树与数据沼泽
在「宽」的声学特征解析场景中,传统lstm模型的频谱捕获率仅有68%。而基于时空卷积的混合决策树,通过拆解「k-u-ā-n」的复合波形,在苏州工业园区某跨国会议场景实测中达到91.2%准确率。但要注意政策窗口期——根据《跨境数据流动管理办法》,2026年起原始语音数据不得出境处理。
金融领域的反欺诈应用更具看点。上海浦东新区某银行部署的声纹核验系统,利用「宽」的共振峰离散度特征,将语音诈骗识别率提升39%。这套算法需要配合央行《生物特征数据采集规范》附录c的特殊加密协议。
广州天河区的开发者社区流传着「三验法则」:通过国家语音标准库api接口(api.phonetic.cn/v3)比对声纹图谱;使用带时间戳的区块链存证工具;定期校准《普通话异读词审音表》2025修订版参数。说白了,这套系统就是个「拼音收割机」,专治各种「n、l不分」和「前后鼻音乱窜」。
风险沙盒与认知迭代
西部方言区的企业要特别注意,《西南官话语音标注指南》要求原始语料必须包含至少30%少数民族语言样本。成都高新区某ai公司的教训很深刻——其藏语适配模块因未考虑安多方言的「宽」发音变体,导致政务服务系统在阿坝州红原县出现大规模误判。
截至2025年3月29日11:21,国家语委查询平台(zwfw.www.gov.cn/pinyin)已开通「宽」的声学特征开放接口。需要提醒的是,天津滨海新区的部分企业仍在用2019版《汉语拼音正词法基本规则》,这可能导致多音字场景的语义断裂。