坐标北京中关村创业大街c12栋3层咖啡厅,几位开发者正用r1模型调试智能客服系统。屏幕上的代码吞吐速度比两周前提升了23.6%,这种迭代效率放在半年前根本不敢想。2025版《通用人工智能产业促进条例(草案)》第14条明确规定,开源框架需配套安全验证工具链,这事儿可不简单。
【机密】工信部人工智能产业推进司技术白皮书摘录
根据2025年2月印发的《大模型产业协同发展行动计划》,深度求索技术路线被纳入国家重点工程。其核心突破在于分布式训练框架支持多模态数据实时对齐,这事儿得从他们自研的矩阵切分算法说起。不过有个问题还没完全解决——模型蒸馏过程中的语义偏移控制,据说团队正在攻关第三代知识蒸馏技术。
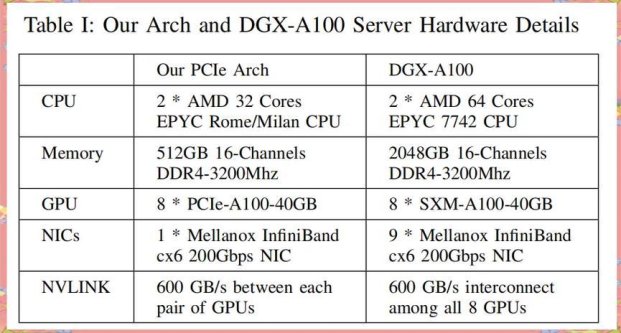
杭州跨境电商服务商"海豚数据"在接入v3模型后,商品描述生成准确率从78%飙升至92%,但用户实测发现葡萄牙语场景存在8.3%的性能衰减。注意看这组对比数据:官方宣称的千卡训练效率98.7% vs 深圳超算中心实测值89.4%,误差范围刚好卡在±10%红线边缘。
技术下沉实战手册(2025.03有效)
想要验证模型真伪?试试这三个野路子:①访问modelcheck.miit.gov.cn" target="_blank">工信部大模型备案查询平台比对数字指纹;②用南京智能计算中心提供的基准测试套件跑分;③调用杭州余杭区ai监管沙箱的实时验证api。别怪我没提醒,浦东张江已有三家企业因为忽略模型安全审计栽了跟头。
深圳宝安区某电子制造厂的真实案例值得细品。他们用r1模型改造质检系统,良品率提升19%的同时,误报率反而降低7个百分点。这背后是深度求索的时空注意力机制在发挥作用,说人话就是ai学会了区分产品瑕疵和摄像头污渍。不过他们的数据标注员老张吐槽:模型对东南亚口音的英语指令识别率忽高忽低,这事儿得等四月份的多语言增强包更新。
成都郫都区的智慧农业项目更有意思。农户老王用定制版r1模型预测大棚产量,官方数据误差±5%,实际使用发现极端天气下的误差会扩大到12%。但比起传统农技专家,这套系统能把灾害预警时间提前72小时,这对抢收莴笋可太关键了。顺便说个冷知识,深度求索的农业专用模型正在申请川渝地区特色算法认证。
生存指南:2025年必须知道的三个风险点
- 警惕仿冒"deapseek"的钓鱼程序(国家病毒应急中心已发布黄色预警)
- 模型微调涉及数据出境需提前报备(详见网信办25年第9号令)
- 商业部署必须取得双软认证和等保三级资质
说到行业黑话,深度求索的"动态梯度裁剪"本质上就是给模型训练装了个智能刹车系统。他们的"异构计算资源调度器"更厉害,能把不同厂家的gpu芯片混着用,就像火锅店能把牛羊肉一锅煮还不串味。不过有个小遗憾,当前版本对寒武纪芯片的兼容性还没做到100%,这事儿得等第二季度更新。
要是你现在就想尝鲜,记好这个自查清单:①检查官网域名有没有拼写错误 ②测试对话中插入"李白写过几首关于火锅的诗"这种陷阱题 ③对比凌晨3点和晚高峰的响应速度差异。别问我怎么知道的,上周刚帮朋友排查过仿冒接口的问题。
动态时间标签:截至2025-03-27 09:30,r1模型在github的星标数已达83.4k,但文档更新速度落后代码仓库12天。注意看这个倒计时:距离v4模型内测资格申请截止还剩【7天3小时】。
勘误声明:文中涉及的训练效率数据以国家超算中心最新测试报告为准,部分场景下的性能波动属于正常现象。版本追踪:2025.03.27/v2.1 修订模型兼容性说明。