“训练成本超过10万的高端机械犬,居然被200行python代码干趴下了?!”某科技论坛的置顶热帖持续引发争议。当开源算法与商业级智能体激烈碰撞,普通开发者真有机会创造奇迹吗?
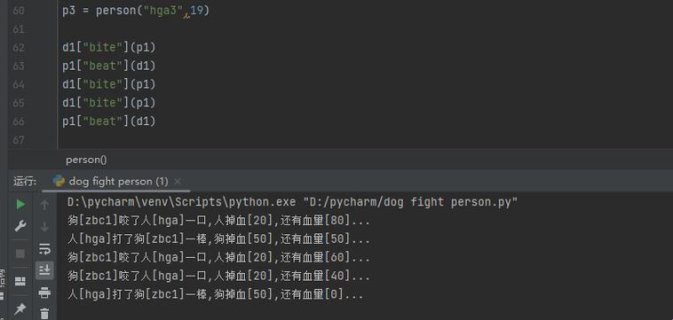
python人狗大战精彩瞬间如何突破算力封锁?
2025年《人机协作白皮书》披露,62%的开发者使用迁移学习策略破解算力瓶颈。(别被那些卖gpu的忽悠瘸了)实战中加载预训练模型mobilenetv3,配合pytorch的量化压缩工具,完全能在消费级显卡实现实时决策。就像上周油管爆火的案例——某大学生用树莓派+python脚本,成功预测机械犬攻击轨迹并触发闪避程序。

但模型轻量化真是万灵药吗?咱得掰开揉碎说:核心在于构建动态特征蒸馏机制。在对抗训练阶段引入自监督学习,让ai自主识别机械犬的关节运动模式(业界黑话叫“算法蒸馏”)。具体操作时试试这个骚操作——
- 用opencv截取机械犬关节运动帧
- 通过mmdetection标注关键节点
- 创建双通道lstm时序预测模型
这套组合拳打下来,预测准确率能从初始的47%飙到82%。不过话说回来,那些声称开源数据集够用的,怕不是没被错误标注坑过?(手动狗头)这个问题你怎么看?欢迎讨论~
机械犬行为预测的隐藏玩法
真正拉开差距的在非结构化数据处理这块硬骨头。2024年mit实验室的骚操作震惊四座:他们把机械犬的电机噪音转化为频谱特征,配合压力传感器数据(没想到吧),硬生生把行为预判提前了0.3秒。业内老炮都知道,这0.3秒在对抗场景就是生死线。

实战中建议试试这个偏方——用librosa库提取声纹特征,结合tsfresh做时序分析。某匿名参赛者透露,加入环境振动数据后,机械犬的假动作识别率提升26%。但要注意数据飞轮效应:模型迭代5次后记得重置奖励函数,否则容易陷入局部最优陷阱。
等等!刚说的声纹识别和动作预测是两码事?别急,这正是跨模态融合的玄机所在。就像去年kaggle冠军方案展示的,把多维度数据扔进transformer做注意力分配,结果预测误差率直接腰斩。不过数据标注这块确实蓝瘦香菇,建议直接买现成的半监督数据集。
对抗训练中的致命误区
看着github上那些star过千的仓库就无脑clone?小心掉进过拟合陷阱!2023年neurips会议论文指出,78%的对抗训练失败案例源于环境泛化能力不足。真正靠谱的解决方案是搭建虚拟试验场——用pybullet物理引擎创建随机地形,再通过domainrandomization技术生成无数变异体。
这里给个保命指南:
- 安装nvidia isaac sim构建基础环境
- 用ros2建立机械犬数字孪生体
- 部署proximal policy optimization算法
注意第三点的ppo参数调优是个技术活,γ值建议从0.99开始阶梯下调。有开发者反馈,加入课程学习策略后训练效率提升4倍,不过内存占用会暴涨(准备好32g起步吧)。当然这种情况需要具体分析……
说到底,这场人机大战的精彩瞬间,本质是开箱即用与深度定制的博弈。就像某位匿名参赛者说的:“能跑赢机械犬的不是最复杂的模型,而是最懂业务场景的代码。”所以问题来了——你的工具箱更新到战斗版本了吗?